Neural Network Audio Noise Reduction

Acoustic Noise Cancellation By Machine Learning Noise Cancelling

Acoustic Noise Cancellation By Machine Learning Noise Cancelling
Practical Deep Learning Audio Denoising Thalles Blog

Sound Classification Using Deep Learning Deep Learning Learning
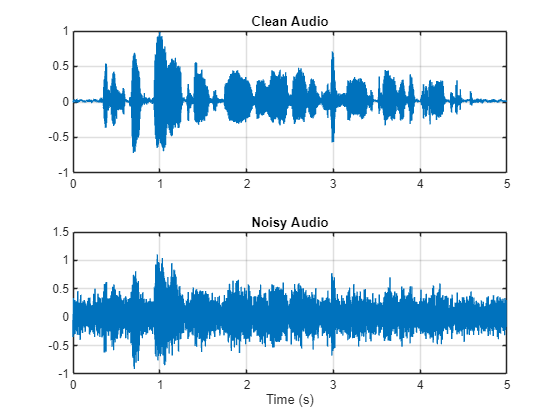
Denoise Speech Using Deep Learning Networks Matlab Simulink

Clean Up Your Speech And Vocal Recordings With Accentize Voicegate

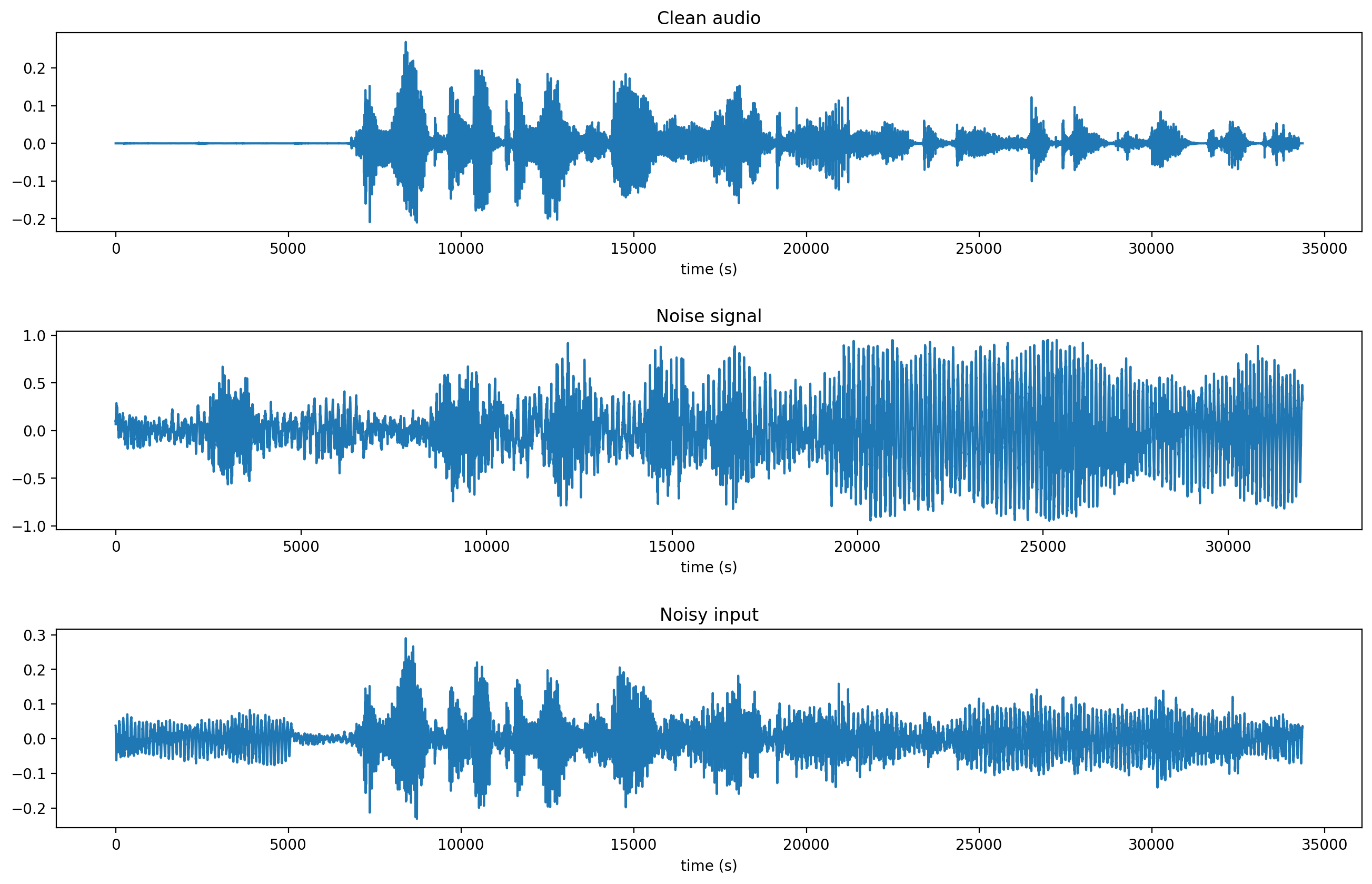
We introduce a model which uses a deep recurrent auto encoder neural network to denoise input features for robust asr.
Neural network audio noise reduction. Adding noise during training is a generic method that can be used regardless of the type of neural network that is being. But of course modern methods of deep learning is applicable to this problem. While it is meant to be used as a library a simple command line tool is provided as an example. Among the various machine learning methods the artificial neural networks.
Rnnoise is a noise suppression library based on a recurrent neural network quick demo application. To compile just type. The model makes no assumptions about how noise affects the signal nor the existence of distinct noise environments. Usually the noise reduction is done using regular signal processing methods such as spectral subtraction due to demand for low latency.
Rnnoise is a noise suppression library based on a recurrent neural network. The model makes no assumptions about how noise affects the signal nor the existence of distinct noise environments. Neural network to denoise input features for robust asr. Click on the link below to let us record one minute of noise from where you are.
This noise can be used to improve the training of the neural network. Machine learning is currently a trending topic in various science and engineering disciplines and the field of geophysics is no exception. Make install while it is meant to be used as a library a simple command line tool is provided as an example. As a side benefit it means that the network will know what kind of noise you have and might do a better job when you get to use it for videoconferencing e g.
Yes it is possible. The model is trained on stereo noisy and clean audio features to predict clean features given noisy input. The type of noise can be specialized to the types of data used as input to the model for example two dimensional noise in the case of images and signal noise in the case of audio data. The common approach adopted by these works is to rst add articial noise to clean audios and then feed the time aligned clean and noisy audio pairs to a neural network for it to learn a mapping.
The model is trained on stereo noisy and clean audio features to predict clean features given noisy input. Autogen sh configure make optionally. Add noise to different network types. The network is able to remove the noise from the curves to a relatively high level but when i attempt to use some validation data on the network it states that i need to have input data of the same dimensions which makes me think it s considering all 300 peaks to be one data set.

Automatic Speech Recognition As A Microservice On Aws With Images
How To Build A Deep Audio De Noiser Using Tensorflow 2 0 By

An Introduction To Audio Electronics Sound Microphones Speakers

Endpoint Discontinuities And Spectral Leakage Discrete Fourier

Understanding Dolby And Dts Surround Sound Formats In 2020

Creators Now Have An Easy Way To Incorporate Ai Into Their

Pin On Audio

Introducing Wav2latter Learning Technology Data Science Deep

Duplicate Songs Detector Via Audio Fingerprinting Codeproject
Msi Sound Tune Delivers Revolutionary Ai Powered Noise

Audionamix Instant Dialogue Cleaner Ai Powered Noise Remover

Noisehush I9 Active Noise Cancelling Bluetooth 4 1 Headphones

Electromagnetic Compatibility Engineering Electromagnetic
